La entrada de hoy está inspirada en explicar con más detalle la idea que expresa la frase más cosas y nuevas cosas, que describe uno de los resultados del cambio socio tecnológico estimulado por la adopción masiva de Internet, telefonía móvil, redes digitales que hicieron las personas en Chile y el mundo. En términos específicos el contenido está asociado con entradas anteriores que abordaron la difusión de los signos de puntuación (sobre puntos y comas) y el análisis del libro del Quijote de la Mancha (Quijote 2.0). Ambas presentaron la noción de hacer nuevas cosas con el análisis de texto en temas y variables de interés, tales como, el uso de los signos de puntuación, establecer las familias de palabras presentes en ciertos textos seleccionados, examinar muchos textos de una vez, establecer palabras (claves) que definen ciertos fenómenos o contextos y otras más. Se trata de hacer más y nuevas cosas con los recursos digitales a nuestro alcance, entendiendo que hoy portamos un smartphone conectado a Internet con el que accedemos a redes digitales y otros recursos tecnológicos.
Pensando en comunidades que cooperan con datos de textos porque comparten el interés en el tema y para profundizar en esta dirección, hoy ilustramos el análisis de texto con un ejemplo basado en datos del Proyecto Gutenberg. Es una biblioteca digital que funciona desde el año 1971, reúne a 70.000 textos escritos en inglés y en otros idiomas (alemán, italiano, español, francés, chino, etc.). Gutenberg constituye una comunidad de colaboradores fundamentalmente voluntarios y ha sido el primer proveedor de libros electrónicos (eBooks). Es una iniciativa dedicada a archivar y digitalizar libros y, textos en general, que surgió de la decisión del escritor norteamericano Michael S. Hart con la finalidad de fomentar la creación y distribución de los libros electrónicos. Los libros están en formato abierto, relativamente fáciles de usar porque tienen dominio público en Estados Unidos, que hace que sean gratuitos al no estar sujetos al pago de derechos.
A continuación, el Gráfico 1 presenta la comparación de la frecuencia de uso de palabras de tres autores españoles: Miguel de Cervantes (1547-1616), Pedro Calderón de la Barca (1600-1681), Pío Baroja (1872-1956). El análisis emplea a Miguel de Cervantes como referencia (eje Y) en las dos gráficas que componen el Gráfico 1. La comparación aborda un total de 106.404 palabras que provienen de cuatro libros de Cervantes, cuatro de Calderón de la Barca y cinco de Baroja. Todos los ejemplares están disponibles en el Proyecto Gutenberg. Cada punto del gráfico corresponde a la frecuencia de ocurrencia de una misma palabra en el corpus de libros de cada escritor. Debido al amplio rango que poseen las frecuencias de palabras en los textos se utilizan escalas logarítmicas que van de 0,001% al 10 %. En el gráfico se incluye una línea segmentada para ayudar a la visualización, la que separa diagonalmente el gráfico en dos áreas iguales. Respecto al formato de las palabras, éstas se presentan en letras minúsculas y carecen de tildes.
Gráfico 1. La frecuencia de palabras en libros de tres escritores españoles.
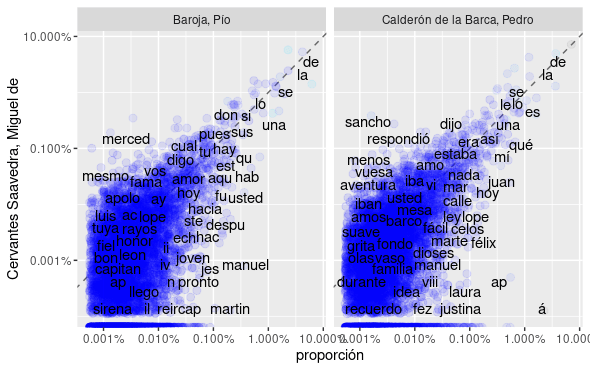
Fuente: Elaboración propia con las palabras de los libros seleccionados de los autores, datos disponibles en el Proyecto Gutenberg.
Al observar el Gráfico 1 el primer elemento que surge es que las palabras se distribuyen mayoritariamente en los cuadrados en torno a la diagonal, esto es, en los cuadrados cuyos lados (en el eje X e Y) representan los mismos porcentajes, por ejemplo, el cuadrado superior derecho del primer gráfico contiene las palabras con una frecuencia de ocurrencia entre 1% y 10% en el corpus de Cervantes y Baroja. El siguiente cuadrado diagonal, que está hacia abajo y a la izquierda, corresponde a todas las palabras con una frecuencia de ocurrencia de 0,1% a 1% y así sucesivamente. Cabe destacar que este patrón aparece en ambos gráficos de la comparación y está conformado por distintos grupos de palabras. El segundo elemento que nace de observar el gráfico por los cuadrados diagonales, de derecha a izquierda y de arriba hacia abajo, muestra que va aumentando la cantidad de palabras circunscritas en un cuadrado y también va en aumento la variabilidad. Es decir, primeramente, las pocas palabras que contiene el cuadrado diagonal se ubican en torno a la línea diagonal. En el siguiente cuadrado ellas van cubriendo parcialmente el área del cuadrado. A continuación, las palabras ocupan toda el área del cuadrado y una parte de los cuadrados adyacentes. Por ejemplo, el cuadrado diagonal del extremo inferior izquierdo (con palabras de frecuencia de ocurrencia entre 0,001% y 0,01%) está totalmente lleno de palabras, que alcanzan a cubrir una parte de los cuadrados vecinos.
¿Por qué sucede así? Se observa que el cuadrado superior derecho (1% a 10% de ocurrencia) contiene pocas palabras y son las mismas en ambos gráficos. Corresponden a los artículos y preposiciones de la lengua española (de, la, en, una, por, etc.), palabras que permiten dar cierta estructura a los textos independientemente de su contenido. Una forma de pensar este punto es que cada uno de los cuadrados diagonales corresponde a una escala distinta, las palabras que contienen ocurren diez veces más o diez veces menos que el cuadrado diagonal vecino. El siguiente cuadrado diagonal (0,1% a 1% de ocurrencia) mantiene una lógica similar en relación a las palabras, pero no a la variabilidad. Aquí advertimos que empieza a ser significativa la obra del autor, la particularidad de sus contenidos. Por ejemplo, en relación a los personajes principales, los lugares donde se desarrolla la obra, entre otros. Los dos cuadrados siguientes (0,01% a 0,1% y 0,001% al 0,01%) contienen numerosas palabras que ocurren pocas veces, por ejemplo, en el corpus utilizado, con aproximadamente 100.000 palabras, en estos cuadrados están aquellas que aparecen entre una a cien veces. Esto explica su alta variabilidad, porque en el corpus de un autor una palabra puede aparecer tres veces y en el del otro treinta veces, en este caso la palabra no estará ubicada en un cuadrado diagonal, sino que en uno adyacente. Esto se aprecia claramente en los nombres propios de personajes, que son las palabras principales en la obra de un autor y no en el otro, por ejemplo “martin” y “manuel” en Baroja; “justina”, “laura”, “manuel” en Calderón de la Barca y “sancho” en Cervantes.
¿Por qué se puede hacer el trabajo del ejemplo? Esta entrada ilustra con este ejemplo lo que significa que se puedan hacer más o nuevas cosas producto del cambio socio tecnológico actual. En él se combina un conjunto de elementos propios de este cambio. El primero es el mundo Wiki que surge porque la caída de los costos de transacción permite que muchas personas y grupos que comparten intereses específicos en algún tópico conformen comunidades que colaboran aportando datos (textos, cifras, otros), análisis específicos y/o determinadas metodologías que permiten a otros resolver algunos problemas concretos. El ejemplo clásico de proyectos de colaboración es la enciclopedia Wikipedia. También en esta línea se puede mencionar el Proyecto Maddison cuyos datos ocupamos en la décima entrada del blog. La presente entrada ocupa los datos que recopila y administra el Proyecto Gutenberg. En esta perspectiva una vez que obtuvimos los datos en la biblioteca digital se procedió a su procesamiento, para lo cual nos apoyamos en las notas sobre la minería de texto que Qiushi Yan (2020) publicó en la plataforma Bookdown. Y en la herramienta de procesamiento RStudio en la nube (Posit). Luego, publicamos el contenido en este Blog que lo soporta WordPress. Esperamos que su resultado motive a otras personas y esta entrada sea combinada con otras fuentes generando así nuevo contenido. De esta manera la entrada encarna el espíritu de la colaboración en red.


Deja un comentario