En el conjunto de consecuencias del cambio socio tecnológico figura la enorme producción de datos generada por las personas, grupos, empresas e instituciones. Los datos masivos – Big data – son resultado de la reducción del costo de registro, almacenamiento, filtro y selección. El Big data no es sólo una gran cantidad de datos (Big), también significa que la data es permanente. «Lo Big» necesita una capacidad de selección para tener utilidad. «Lo permanente» provoca que las interacciones humanas, mediadas digitalmente, no desaparezcan al quedar almacenadas en el espacio digital. De ser interacciones análogas, en que gran parte de la interacción no quedaba registrada, ahora pasan a ser interacciones que no desaparecen y adquieren historia. Por ejemplo, las interacciones que quedan registradas en Twitter o WhatsApp transformándose en un dolor de cabeza para algunas autoridades y figuras públicas.
Nos preguntamos ¿tienen algún potencial de uso estos datos ?, ¿podemos hacer algo más con los datos que tenemos? La entrada presenta los aspectos a tener en cuenta para responder afirmativamente a las interrogantes. Las preguntas apuntan a la capacidad de selección para otorgar utilidad a la abundancia de datos, esto es, extraer el valor que tienen (pueden llegar a tener) en distintos ámbitos. Mayer-Schonberger y Cukier (2015) señalaron que muchos datos acopiados en el ciberespacio tienen un valor potencial, aunque tal como están almacenados no es posible trabajar directamente con ellos. Para sacarles provecho es necesario prepararlos, para Mayer-Schonberger y Cukier eso significa que los datos se deben “datificar”. No existe un término adecuado para nombrar la transformación del dato desde el registro. Datificar un fenómeno es plasmarlo en un formato cuantificado para que pueda ser tabulado y analizado (Mayer-Schonberger y Cukier, 2015, p.100). Los datos requieren datificación para ser analizados y complementados con nueva información. Cuando el dato es datificado admite ser registrado, analizado, reorganizado. La datificación mejora además la calidad (exactitud, integridad, coherencia, confiabilidad, accesibilidad) del conjunto de datos.
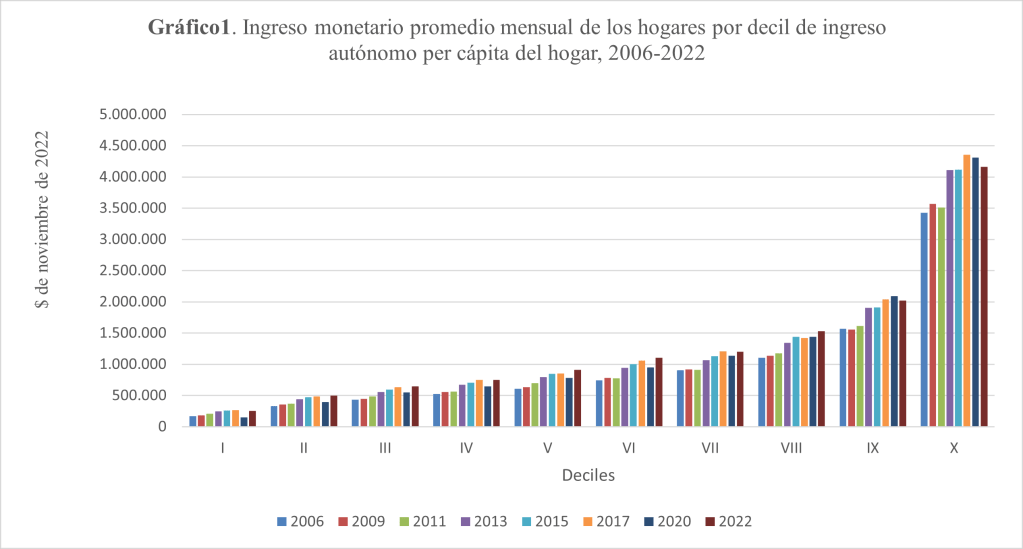
La entrada aborda la datificación mediante un ejemplo sencillo que utiliza datos de la Encuesta Socioeconómica Nacional (CASEN) de 2022. La encuesta se aplica desde el año 1990 con una periodicidad de dos y tres años. Su principal objetivo es dar seguimiento a los cambios socioeconómicos de la sociedad chilena y caracterizar la situación de los hogares en relación a la pobreza, demografía, educación, salud, vivienda, ocupación, ingresos. A continuación, recreamos uno de los resultados de la encuesta CASEN 2022, se trata del ingreso monetario mensual por decil de ingreso autónomo per cápita del hogar, 2006-2022 (En Resultados ingresos Casen 2022.pdf, p. 16). Para lo cual se utilizaron los datos de las últimas encuestas (2006, 2009, 2011, 2013, 2015, 2017, 2020, 2022). Tal como especificamos en la entrada Primera mirada a los datos públicos los datos van experimentando transformaciones en el tiempo: nacen, mueren y permanecen dejando una huella digital (Hilbert, 2013). En la dinámica que experimentan suelen presentar problemas que afectan su calidad y requieren ser resueltos.
Fuente: Elaboración propia con datos de Resultados de ingresos Casen 2022, Observatorio Social MDSF.
El Gráfico 1 presenta la reproducción del ingreso monetario mensual por decil de ingreso autónomo per cápita del hogar, período 2006-2022. La reproducción de resultados oficiales es uno de los primeros pasos en cualquier investigación científica. El cálculo corresponde al promedio ponderado del ingreso monetario corregido del hogar según deciles del ingreso autónomo. Al realizar la operación una primera dificultad surge con el nombre de las variables, pues no son las mismas en todas las encuestas. Por ejemplo, la variable que almacena el ingreso monetario en las encuestas cambió de nombre en varias oportunidades: YMONEHAJ (2006 y 2009), ymonehaj (2011), ymoneCorh (2013), ymonecorh (2015-2022). Lo mismo sucede con las otras dos variables necesarias en el cálculo: factor de expansión y deciles. Estas mantienen sus nombres (expr y dau), pero en algunas encuestas se registran con letra mayúscula y en otras en minúsculas. Adicionalmente, para hacer la comparación de las cantidades se debe considerar la variación de IPC. Más la consideración de la composición de población que exige una adecuación que emplea las Proyecciones de Población del Censo 2017. Todas estas dificultades prácticas impiden la automatización de los cálculos y provoca dos problemas: (1) en el ámbito de datos masivos esas “dificultades prácticas” implican que su reparación importe uno de los costos más altos en el análisis de la ciencia de datos. Los estudios señalan que en promedio la actividad ocupa el 50% del tiempo. (2) La dificultad de visualización de los datos por más usuarios. Este aspecto tiene gran importancia porque aumenta las capacidades humanas, en lugar reemplazar a la gente con métodos computacionales en la toma de decisión (Anscombe, 1973).
La utilización de los datos de un conjunto de encuestas CASEN requiere una preparación previa al trabajo de análisis. La datificación es un proceso que permite minimizar la preparación y adecuación de los datos de forma que el trabajo de análisis se pueda potenciar. La datificación, en general, es un proceso que se desarrolla poco a poco, se va imponiendo por la necesidad de dar coherencia a un conjunto de datos, por ejemplo, entre todas las encuestas CASEN. Otra fuerza que estimula la datificación es la integración de un cuerpo de datos con otras fuentes de datos de nivel local o internacional. Así los datos se pueden ser utilizados en estudios comparativos; en el seguimiento de información de ámbitos específicos (trabajo, educación, etc.) que precisan las instituciones internacionales; y en las estadísticas de entidades internacionales en las cuales Chile participa. A nivel internacional el proceso genera requerimientos en la estandarización de actividades. A nivel local los datos de las encuestas están asociados a territorios de regiones y comunas, entonces resulta obvio registrar las regiones, provincias y comunas según los códigos territoriales vigentes, como el Código Único Territorial de 2018 que incorporó abreviaturas para cada región, por ejemplo, la región del Biobío (sic) se abrevia BBIO. También en el ámbito nacional observamos la normalización en educación y ocupación. En el ámbito internacional la encuesta CASEN incorpora en el Módulo Educación la Clasificación Internacional Normalizada de Educación (CINE) de la UNESCO, el marco de referencia para recopilar, comparar, analizar estadísticas de educación internacionalmente. Las actividades productivas y la ocupación se clasifican según la norma de Clasificación Internacional Uniforme de Ocupaciones (CIUO 08) que actualiza la Organización Internacional del Trabajo (OIT). Entonces, agregar valor a los datos disponibles significa datificarlos para que haya coherencia entre ellos de modo de administrar su ciclo de vida y que puedan integrarse con otras fuentes de datos.


Deja un comentario